记录一次如何自己使用国外服务器搭建梯子
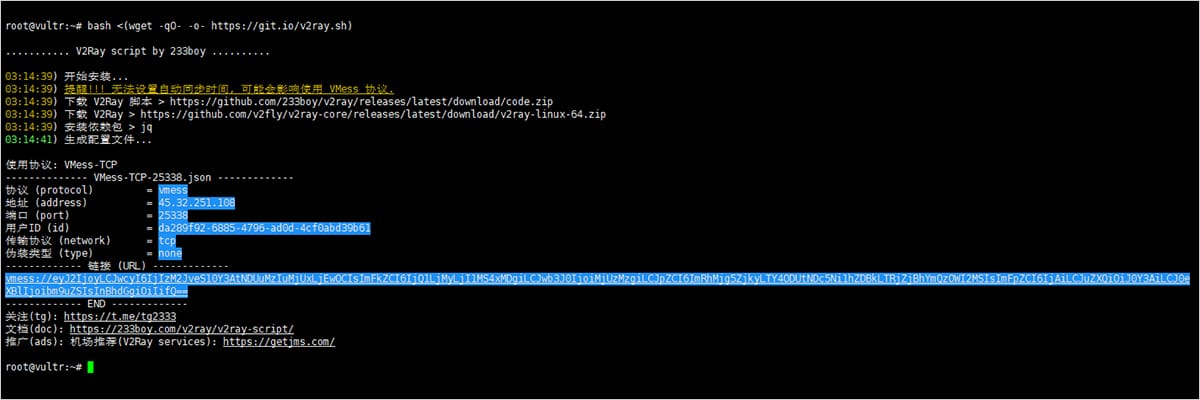
机缘巧合之下,租了一台亚马逊的美国服务器,想着这么大的服务器不能就跑一个业务吧,得利用起来,于是,就开始了搭建梯子之旅。 第一步:使用root账号登上ssh服务器。 第二步:执行一键搭建脚本: bash <(wget -qO- -o- https://git.io/v2ray.sh)...
【已解决】Element Plus的el-select组件默认值显示问题:value而非label的解决方法
在使用Element Plus的el-select组件时,有时会遇到一个令人困惑的问题:组件的默认值显示的是value,而不是我们期望的label。这个问题可能会给开发者带来不必要的困扰,特别是在一些对展示内容要求严格的场景下。 首先,我们需要明确一点:el-select组件的默认显示内容是由其绑定...
C#使用SendMessage传递字符串时,String与IntPtr的转换
使用 IntPtr p = Marshal.StringToHGlobalAnsi(s) 将string类型转换为IntPtr类型...
Visual Studio安装共享组件、工具和SDK位置更改。
今天安装VS的时候遇到一个问题,就是共享组件的安装位置,默认是我以前的位置,在G盘里,但是后面更换了硬盘分区,G盘以及没有了,安装程序里也没提供修改安装路径的地方。去群里问了一下大佬,找到了更改方法: 1、打开注册表 2、进入HKEY_LOCAL_MACHINE /SOFTWARE /M...
【JAVA】Springboot的4种获取请求参数的注解的差异

在Spring Boot中,我们可以使用@RequestParam、@PathVariable、@RequestBody和@RequestHeader等注解来读取请求参数。 @RequestBody用于处理请求体中的数据,通常用于POST或PUT请求,并且请求体中包含JSON或XML格式的数据。 @...
【VUE】深入讨论关于VUE的深拷贝和浅拷贝问题
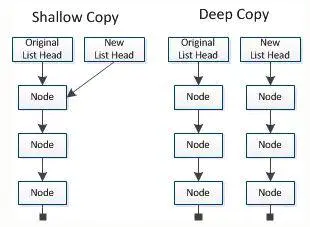
一、深拷贝和浅拷贝的定义:1、深拷贝 :指拷贝对象的具体内容,并且为对象分配新的内存地址。深拷贝结束之后,两个对象虽然存的值是一样的,但是内存地址不一样,互不影响,互不干涉。2、浅拷贝 :指对内存地址的复制,让目标对象指针和源对象指向同一片内存空间。浅拷贝只会拷贝基本数据类型的值,以及实例对象的引用...
【已解决】SQLSTATE[42000]: Syntax error or access violation: 1055 Expression #1 of SELECT list is not in
![【已解决】SQLSTATE[42000]: Syntax error or access violation: 1055 Expression #1 of SELECT list is not in](https://blog.virtualman.top/zb_users/upload/2024/03/202403211711011439605237.png)
改一个老项目,然后配置完成突然就报错了,MySQL是5.7的版本。这个错误是MySQL在严格模式下特有的,当你尝试查询一个表但SELECT语句中列出的某些字段并没有明确出现在GROUP BY子句中时,就会触发这个错误。这是为了防止不确定的结果,因为在没有明确的聚合函数(如SUM、AVG、MAX等)的...
【已解决】PHP报错:could not find driver
在 PHP 中遇到 "could not find driver" 错误通常意味着 PHP 试图使用某个数据库扩展(比如 MySQLi、PDO_MySQL、PDO_SQLite 等),但找不到对应的驱动。这可能是因为扩展没有安装,或者没有正确配置。如果使用的是MySQL数据库,最...
【已解决】Python的Itchat库扫码后,重复刷新导致一直无法成功登录微信
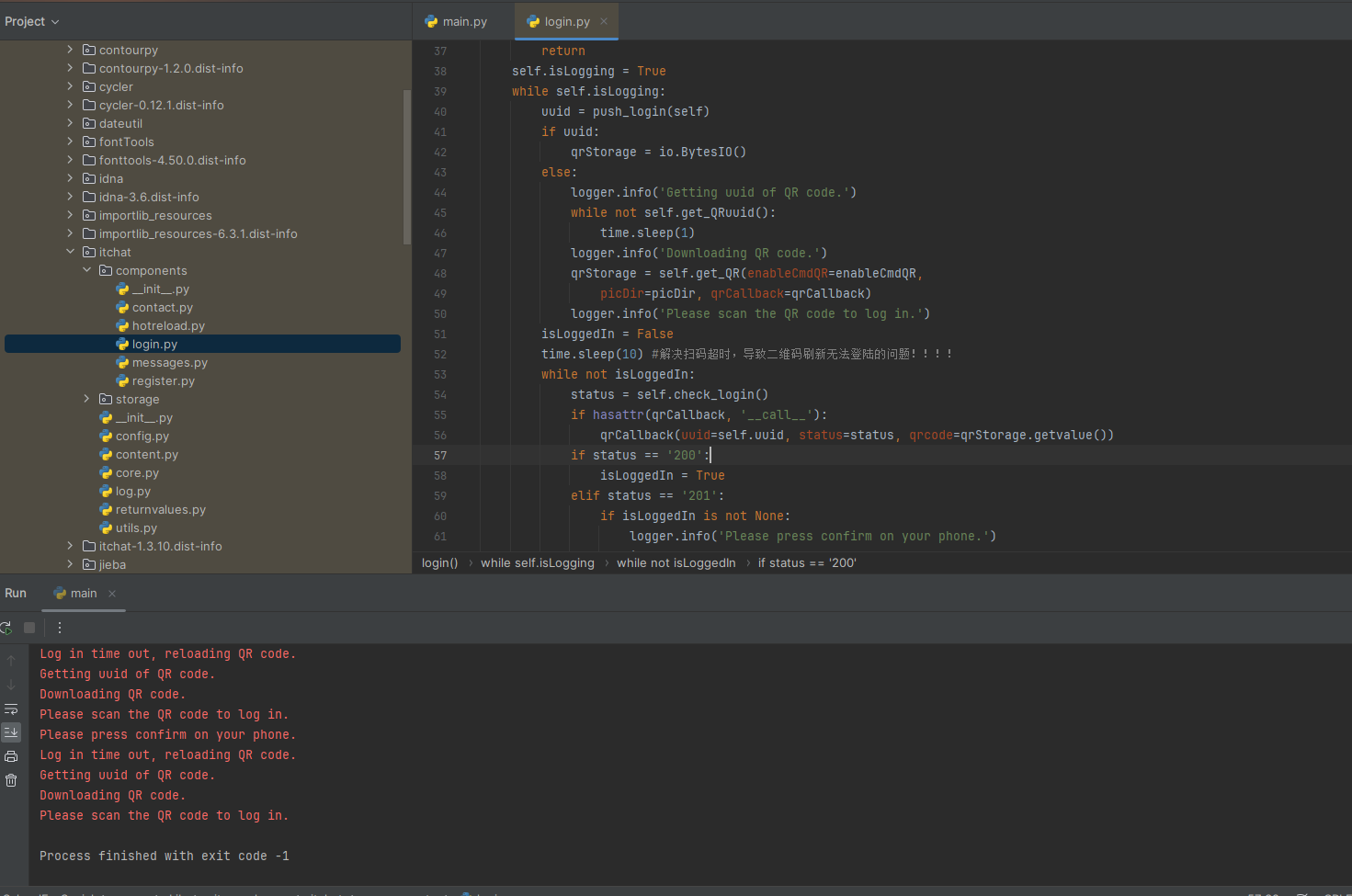
解决方法如下图login.py的第52行代码所示。进入itchat文件夹下的/components/login.py文件。在login.py中增加一行代码:time.sleep(10)...
跑在内存中的数据库——H2数据库

今天接触到了一个非常有意思的数据库,叫H2数据库。在众多数据库中,H2数据库以其独特的特性——内存数据库模式,吸引了大量开发者的关注。今天,就来深入探讨一下这个跑在内存中的数据库——H2数据库。 一、H2数据库简介 H2是一个轻量级的关系型数据库,它支持嵌入式和客户...