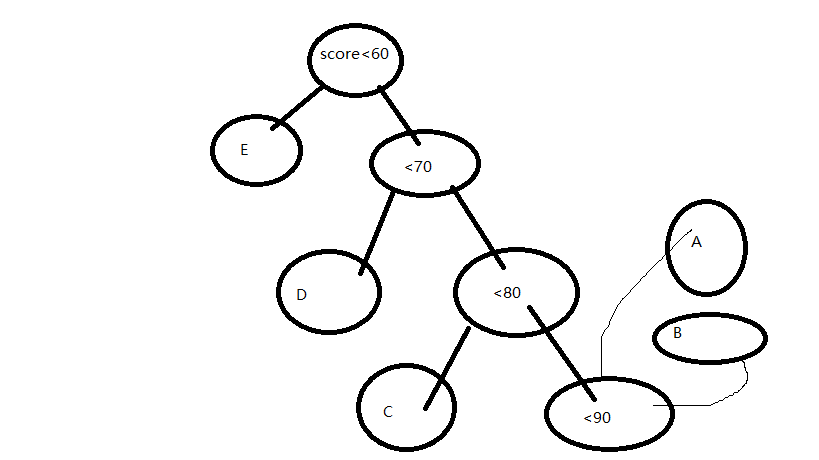
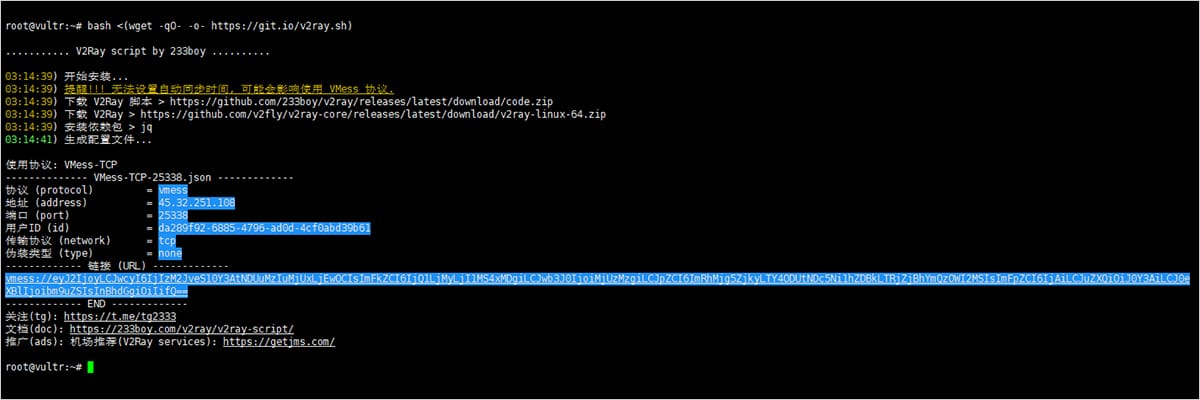
python实现对简单的运算型验证码的识别【不使用OpenCV】
最近在写我们学校的教务系统的手机版,在前端用户执行绑定操作后,服务器将执行登录,但在登录过程中,教务系统中有个运算型的验证码,大致是这个样子的: 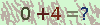
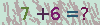
下面我们开始实现这个验证码的识别。
1、图片读取
从网站上下载大量同类型的验证码,人工标记上每个验证码的识别结果
2、图片灰度化、二值化
灰度化,在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。
通过PIL中的算法即可快速实现灰度化:img=img.convert("L")
这样我们就得到了R=G=B的代码
接下来我们要进行二值化,二值化的目的就是把文字和背景部分严格区分开。可以通过尝试的方法,找到一个阈值,然后将RGB大于阈值的置为1,否则置为0。
3、降噪
本次实践并没有用到,因为验证码比较简单,并没有用到此步骤
4、分割
我们根据验证码本身,通过分割割除每一块数字、符号的图片
5、获取样本并计算特征值
接下来我们有了各个数字图片的样本。
如何和新来的图片进行匹配?
我们要通过计算黑色像素点/总像素点的值然后对所有图片都如此操作,分别取 分割出来的6份中第一份的平均值,这样的到了能代表0这个图片的6份数值存起来后面用。
6、识别图片
将计算好的 6个值与我们之前给0-9计算的这个值分别进行比较 找出和0-9最相似的数字 这个数字就是我们想要的结果
完整代码:
import base64
import json
import os
import random
import string
from PIL import Image, ImageDraw
import requests
import ssl
def getimg(filename):
url = "【验证码获取网址已删除】"
r = requests.get(url, verify=False)
# print(r.text)
res = json.loads(r.text)
print(res)
# print(res['content'])
f = open(filename, 'wb')
# 获取动漫头像
anime = res['content'].split(',')[1]
# print(anime)
# 对返回的头像进行解码
anime = base64.b64decode(anime)
# 将头像写入文件当中
f.write(anime)
f.close()
def get_block_score(img):
sum = 0
black = 0
for i in range(img.size[0]):
for j in range(img.size[1]):
if img.getpixel((i, j)) == 0:
black += 1
sum += 1
return black, sum
# 计算特征值
def get_features_vaule_by_img(img):
wide = img.size[0]
one_wide = int(wide / 2)
high = img.size[1]
one_high = int(high / 3)
score_lsit = []
for i in range(3):
for j in range(2):
img_one = img.crop((j * one_wide, i * one_high, (j + 1) * one_wide, (i + 1) * one_high))
black, sum = get_block_score(img_one)
score_lsit.append(black * 1.0 / sum)
return score_lsit
def ez_map(thresold):
res = []
for i in range(256):
if i < thresold:
res.append(0)
else:
res.append(1)
return res
def pre_hd_ez(img):
img = img.convert("L")
# 二值
thresold = 140
table = ez_map(thresold)
# img=img.convert("1")
img = img.point(table, '1')
return img
def pre_split_img(img):
imgs = []
num1 = (20,6,31,21)
fuhao = (36,6,50,21)
num2 = (51,6,62,21)
img_num1 = img.crop(num1)
img_fuhao = img.crop(fuhao)
img_num2 = img.crop(num2)
imgs.append(img_num1)
imgs.append(img_fuhao)
imgs.append(img_num2)
return imgs
filename =""
def Base64ToImage(_base64):
str = random.sample(string.ascii_letters + string.digits, 16)
global filename
filename = ''.join(str) +'.jpg'
f = open(filename, 'wb')
# 获取动漫头像
anime = _base64.split(',')[1]
# 对返回的头像进行解码
anime = base64.b64decode(anime)
# 将头像写入文件当中
f.write(anime)
f.close()
img = Image.open(filename)
return img
fuhao = [ [0.08571428571428572, 0.08571428571428572, 0.42857142857142855, 0.42857142857142855, 0.11428571428571428, 0.11428571428571428],[0.2857142857142857, 0.0, 0.2857142857142857, 0.0, 0.0, 0.0]]
nums1=[
[0.36, 0.44, 0.4, 0.4, 0.36, 0.44],
[0.24, 0.32, 0.0, 0.4, 0.24, 0.56],
[0.32, 0.4, 0.04, 0.4, 0.48, 0.32],
[0.32, 0.48, 0.16, 0.64, 0.32, 0.48],
[0.04, 0.48, 0.36, 0.52, 0.16, 0.44],
[0.4, 0.24, 0.28, 0.48, 0.32, 0.4],
[0.36, 0.32, 0.56, 0.48, 0.36, 0.48],
[0.32, 0.48, 0.04, 0.44, 0.24, 0.12],
[0.4, 0.48, 0.56, 0.64, 0.4, 0.48],
[0.4, 0.44, 0.4, 0.64, 0.24, 0.44]
]
nums2=[
[0.44, 0.36, 0.4, 0.4, 0.44, 0.36],
[0.4, 0.16, 0.2, 0.2, 0.4, 0.4],
[0.4, 0.32, 0.12, 0.32, 0.56, 0.24],
[0.4, 0.4, 0.24, 0.56, 0.4, 0.4],
[0.12, 0.4, 0.4, 0.52, 0.2, 0.44],
[0.48, 0.16, 0.36, 0.4, 0.4, 0.32],
[0.44, 0.24, 0.64, 0.4, 0.44, 0.4],
[0.4, 0.4, 0.2, 0.28, 0.36, 0.0],
[0.48, 0.4, 0.64, 0.56, 0.48, 0.4],
[0.48, 0.36, 0.48, 0.56, 0.32, 0.36]
]
#getimg('result.jpg') # 获取图片
# 先预处理、二值化
def Recognition(_base64):
img = Base64ToImage(_base64)
img = pre_hd_ez(img) # 二值化
imgs = pre_split_img(img) # 分隔
global filename
os.remove(filename)
code_num1 = get_features_vaule_by_img(imgs[0]) # 计算特征值
code_fuhao = get_features_vaule_by_img(imgs[1]) # 计算特征值
code_num2 = get_features_vaule_by_img(imgs[2]) # 计算特征值
# print('code1:'+str( code_num1), 'code2:'+str(code_num2))
a = 0
b = 0
for index in range(0, 10):
if (code_num1 == nums1[index]):
# print(index)
a = index
break
for index in range(0, 10):
if (code_num2 == nums2[index]):
# print(index)
b = index
break
if code_fuhao == fuhao[0]:
print(str(a) + '+' + str(b) + '=' + str(a + b))
return a+b
elif code_fuhao == fuhao[1]:
print(str(a) + '*' + str(b) + '=' + str(a * b))
return a * b
else:
print('符号识别Error')
Recognition("data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAGQAAAAZCAIAAABIPBwcAAACYUlEQVR42uWYPUp2QQyFsxgbO7Hy\nawUXIIKNq7CwcD8uQlyJG3APll64EEJ+Tk5mhK8QUtx33vl95kwmE/n6/P6z9v72cRj/r/yXebia\nZOHC6Ok08L+umjVZWB5TmZxHWjPOcplX1QnfeQ7rd3lV/8YFgM3HS2KGiDp1g46WXMLa1A55BLC4\nsATacgblCqzYshXqJqwKHICFewPiJXXdUhM8AHMKdo5J1Um1baAao0dy80pY7RnGu3R8XNzdO5u6\nLbDnh70+3KilrTDidNlPV9dqM1ikN03XHEkpr/YIH3b77+Uw4E0sqZTXSCZnoSWlxvCS5UtaYbkx\nlBdzXVawHClbQt7CGJYdxeoLuzABXnYay2j5DqyoqVHYxfgg11uEVeGW9saZBn7Oc23C4m/6x+dL\nbNXkV2AtiEvrVz6+vSJTWOe3wiId1hSW9fT4zkFBaXv97cA66WA7a0bX3vLC8S1JCoQmwoe/ZOiI\neS3ASv09HwlXy9FLEMQDJay0DY5Rq64BLNdE6UQ3YUlp87Tw/Dk9hk5WrSD6Y0jySsXFbL6V0hSW\nm0MLy4lrBRbAgR9uKiKHtY1LSVjxQtRjWMXu+B3C57+q5Uvlp/ALMYagzpj0SzyGqbicVUmY0SvP\n+iwAyw0kC5kNVyElReYqLaw0ho6kgOtkTpN+jGCh23CUeBw9jJnXP/ahbVoCvLGZVM8YFgMFzxVL\nmszkgYQns0LXkHyoAM1K+47h95nJprc1gevFfCshu8L2oQIOhOwk7UjV4JwyIy5wTquf2N8zb4D4\nIaN88SgEm/JagDVKP/C8qqF/AD8/f75l3isgAAAAAElFTkSuQmCC")